共分散構造分析(構造方程式モデル:SEM)は多変量解析の手法群のうちで、最新の線形モデルである[1]。回帰分析(1889年)や因子分析(1904年)が100年以上前に開発されているが、SEMは1960年代末に提案された。
初期の発想は下図のように因子分析とパス解析を統合したモデルであるが、理論的な研究が進み、モデルはより一般化されている。

重回帰分析は目的変数が1個の統計モデルである。パス解析はそれを発展させた、複数の目的変数を含む統計モデルである。モデルが複雑になるため、方程式ではなくパス図で表現するため、パス解析という名前がついている。
因子分析は1960年代になってブレイクスルーが起きた。因子分析モデルの推定にあたり、理論的には既に提案されていた最尤法が、実際のアルゴリズムとプログラムとして実現したことをきっかけに、検証的因子分析が登場した。これ以降、従来のいわゆる因子分析は探索的因子分析と呼ばれ、区別されることになった。
SEMはパス解析と検証的因子分析を統合し、柔軟で強力な表現力を持つ、応用範囲の広い統計モデルとして登場した。つまり、パス解析によって自由に変数間の関係をモデル化することができることに加え、検証的因子分析によって観測変数だけでなく潜在変数(構成概念)の間の関係をモデル化できるようになったのである。パス解析は観測変数のみのモデルであったが、SEMは潜在変数と観測変数の両方を、目的変数(従属変数)にも説明変数(独立変数)にも設定できる柔軟性を持つ。
SEMは1970年代にアカデミアで理論的研究が進んだ。1980年代には実用的なソフトウエアが開発され、応用の時代に入った。日本では1990年代に参考書の出版が始まり、普及した。産業界での応用は、日本経済新聞社の企業評価モデルであるPRISMが発表されたことで、定性的な構成概念を含む評価モデルに適用され、応用的な広がりにつながった。
<SEMの例>
- PRISM(優れた会社ランキング)
日本経済新聞の企業評価モデルは1979年からCASMAが運用されてきた。主成分分析(因子分析)と重回帰分析(判別分析)を財務データに適用したモデルである[2]。
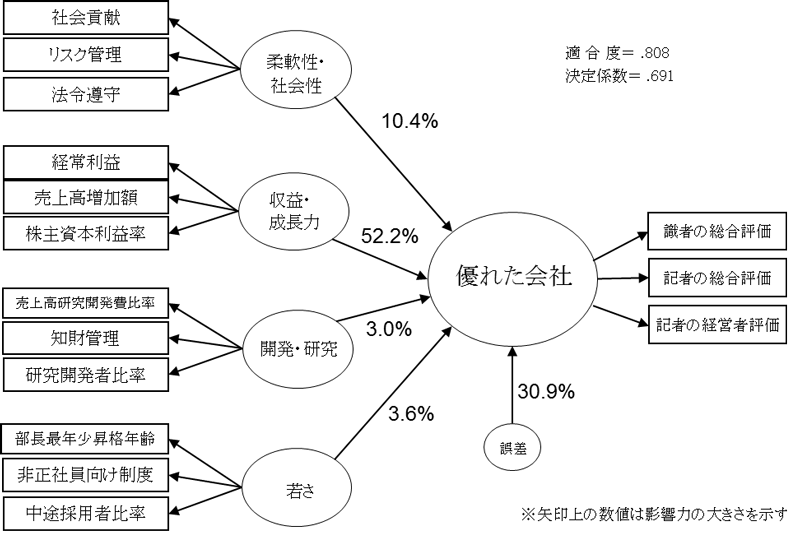
日本経済が1989年末に「バブル崩壊」したことを受けて、日本経済新聞社は新しい企業評価モデルを模索し、日経リサーチとPRISMを共同開発。1994年に第1回の企業ランキングを発表した。CASMAとの相違は、財務データによる収益性や成長力を評価するだけでなく、永続的な成長のための社会性や環境適合性など財務面だけではない定性的側面を評価に盛り込んだモデルにしたことで、そのため潜在変数を導入したSEMが採用されたのである。
下図をパス図といい、方程式ではなくグラフでモデル表現している。潜在変数は円で囲まれ、観測変数は四角で囲まれている。矢印が影響の方向を示す。
- JCSI(日本版顧客満足度指数)
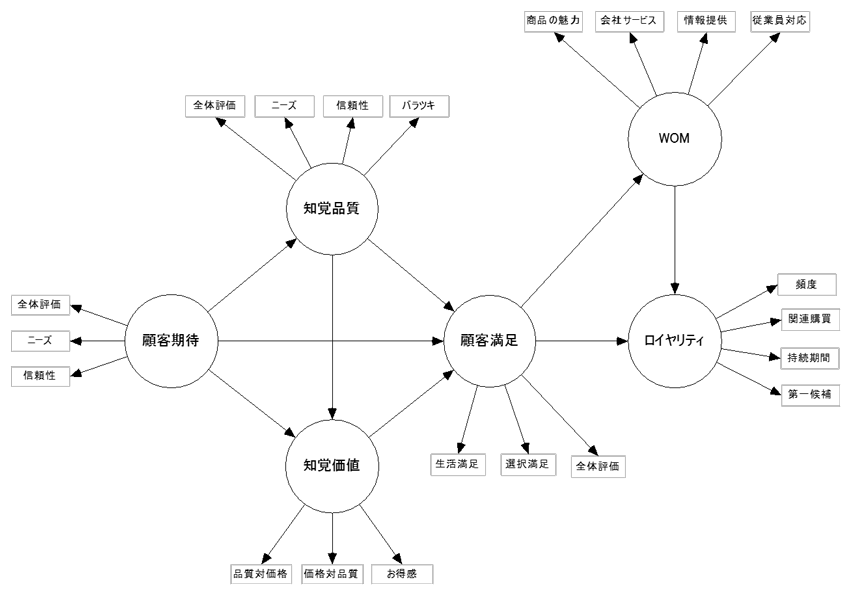
顧客満足度指数(CSI)は各企業のKPIとして独自に作成されているが、経済産業省はサービス産業の競争力強化政策を背景に、顧客満足度を業界横断的に指数化するプロジェクトを立ち上げた。日本生産性本部が受託し、開発委員会(小川孔輔座長)を組織して2009年に日本版顧客満足度指数(JCSI)を開発した(下図)。調査設計・SEMによるモデル構築にあたり日経リサーチの鈴木督久も開発委員として参加した。調査は毎年、サービス産業生産性協議会(SPRING)が実施している。
現在のJCSIモデル、および開発体制は日本生産性本部のWEBサイト(下記)を参照。
http://consul.jpc-net.jp/jcsi/jcsi_causal_model.html
JCSIはOliverが提唱していた期待-パフォーマンスの不一致パラダイム(下図)を下敷にしている。
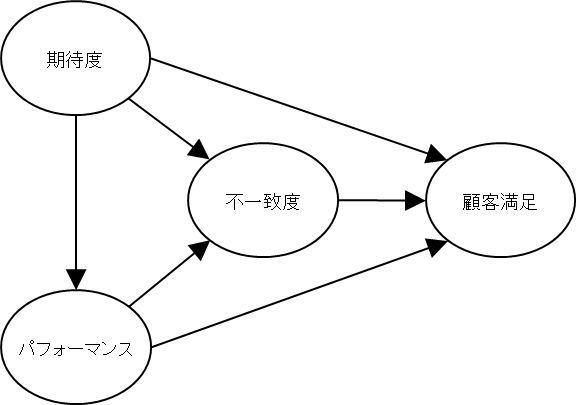
不一致パラダイムは、たとえば以下のような状況である。
- 病院に行くことになった。
- どうせ長時間、待たされると事前に思っている。
- 結果(事後)として、
→ すぐに診察してくれたら、期待に反して大満足!
→ やはり待たされたら、予想通りか・・・。
→ いくらなんでも待たせ過ぎなら、不満をぶつける!
この事前期待とパフォーマンスの差異(不一致)が満足感を規定する、というモデルである。待ち時間の物理的な絶対値ではなく、本人の不一致の心理的な程度に依存すると考える。事前期待の高さ・低さは個人で異なるし、その結果としての満足度も個人で異なる。もちろん、個人の心的状況の集合として、全体としての分布は存在する。
マーケティング分野では不一致モデルをSEMで実証する研究がされてきた。Journal of Marketing Research が1982年にSEMの特集をしたVol. XIX (November)では、Churchill & Surprenantが不一致モデルをSEMで検証した研究を掲載している。この号ではJoreskogやBentlerなどのSEMの専門家も寄稿している。特集企画者はマーケティングリサーチ分野で早くからSEMの応用をしているBagozziである。
- ブランド戦略サーベイのPQ
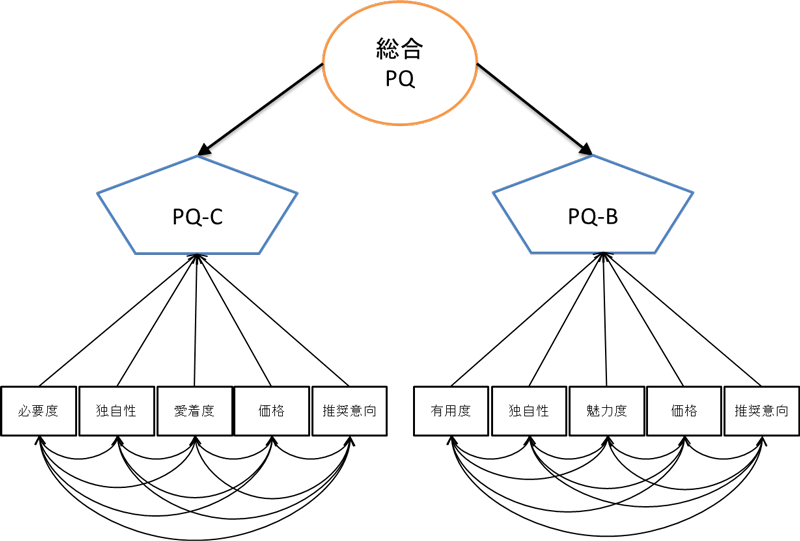
日経リサーチのブランド戦略サーベイは、企業ブランド価値を調査データから構成しており、総合PQ(Perception Quotient:知覚指数)をSEMの検証的因子分析モデルで算出している。PQという名前は、IQ(知能指数)やEQ(感情指数:こころの知能指数)と同様で、企業ブランドの価値が人々のこころの中に、どの程度形成されているかを調査で導いたもの、つまり「知覚されたブランドの価値指数」という意味である。
企業価値は時価総額などの貨幣価値で表現もされるが、ブランド価値を無形価値・資産と考え潜在変数で表現するという観点からSEMを適用した。
調査はコンシューマとビジネスパーソンの二種類で構成され、コンシューマ(PQ-C)とビジネスパーソン(PQ-B)の指数は、5つの調査項目の第1主成分得点である。
<SEMの手順>
- 検証したい仮説に従ってモデルをパス図で表現してみる。これは構成概念(潜在変数)だけで描けばよい。
- 構成概念を測定する指標(観測変数)を考案する。
- データを収集するための調査計画(調査票設計と実査計画)を立案して、調査を実施する。
- 収集したデータに対して仮説モデルを適用して、母数(パラメータ)を推定する。
- 推定した結果(モデル)とデータとの適合を検定・検討する。各種の適合度指標を比較検討することで仮説が成立するか検証する。
- 検証結果によっては、モデルを微修正して適合度を向上させる。しかし、当初仮説を大きく変更することは避ける。それは「仮説はデータで実証されなかった」ということである。

